
 RSS Feed
RSS Feed
|
The next time you hear the airline industry complain that fuels prices are driving up ticket sales, take that excuse with a grain of salt. A previous post looked at cycles in airline prices and traffic, which made some claims about the likely increase of future ticket prices. However, that post did not consider the other determinants of ticket prices. This post will report that capacity is the most economically and statistically significant variable in the short-term. The table below presents results from a regression of growth rates of various components of ticket prices using 205 months of observations. This aggregate data comes from the Bureau of Transportation Services and Energy Information Administration. I use growth rates lagged growth rates instead of levels to avoid a spurious correlation, and I include a lagged ticket price growth to account for some of the additional factors that I may not have included. 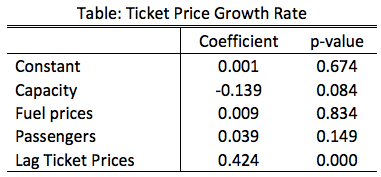 For a 1 percentage point increase in capacity (number of available seats) ticket price growth falls a little over a tenth of a percentage point. Amusingly fuel prices yield a small coefficient with a high p-value. Thus, one can conclude that the previous months fuel prices have a lower impact on current ticket prices than a decline in the number of available seats.
Why is that important? Well, airlines have control over the number of available seats, and less control over the price of fuel. This analysis suggests that they can more than make up for the short-term changes in fuel prices by managing their available seats. The major caveat in this analysis is that pesky qualifier: short-term. It may certainly be the case that the long-term impacts of fuel prices may have significant economic and statistical impacts on ticket prices. In fact, it seems quite likely, but that would require a larger and more detailed data set than the free data I was able to obtain.
0 Comments
A logical analysis of expectations might argue that historical averages drive long-run forecasts with macroeconomic fundamentals and announced policies providing slight mitigation. In contrast, recent economic data drive short-run forecasts. WSJ expected inflation for 2017 provides a good example of this: 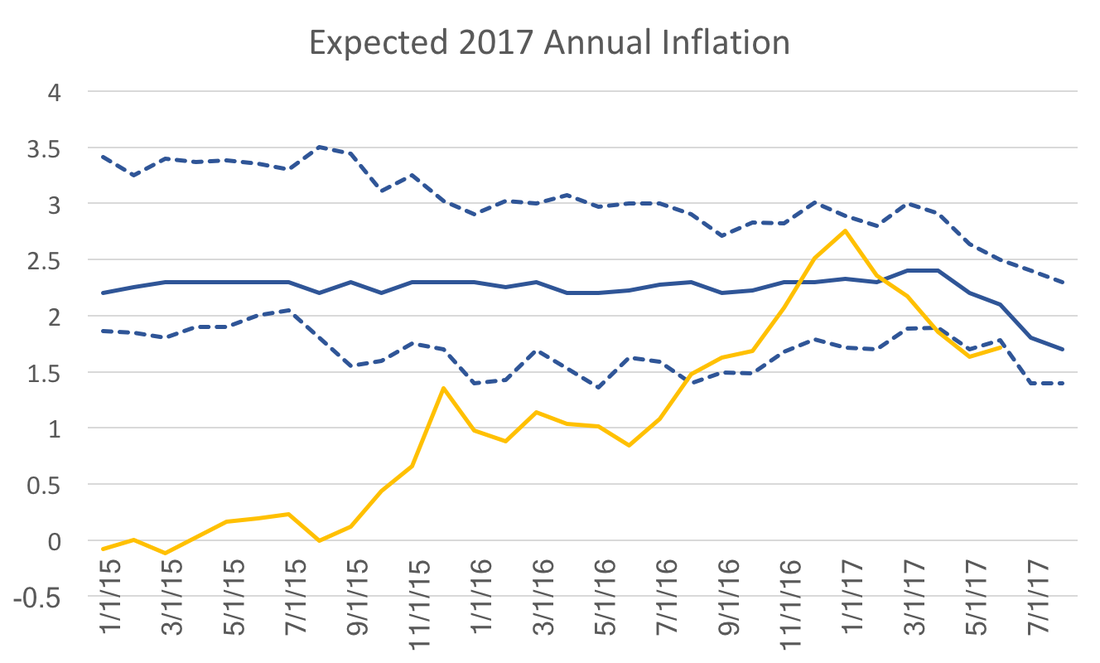 Almost 3 years in advance, the forecasts match the Fed's stated policy and historical averages. At the beginning of the 2017 it looked as though year over year CPI inflation (yellow line) and expectations were converging. However, the last few months of slow price growth have caused expectations to dip following, with a lag, the path of year over year inflation. This post points out that this pattern of behavior need not exist for all variables. 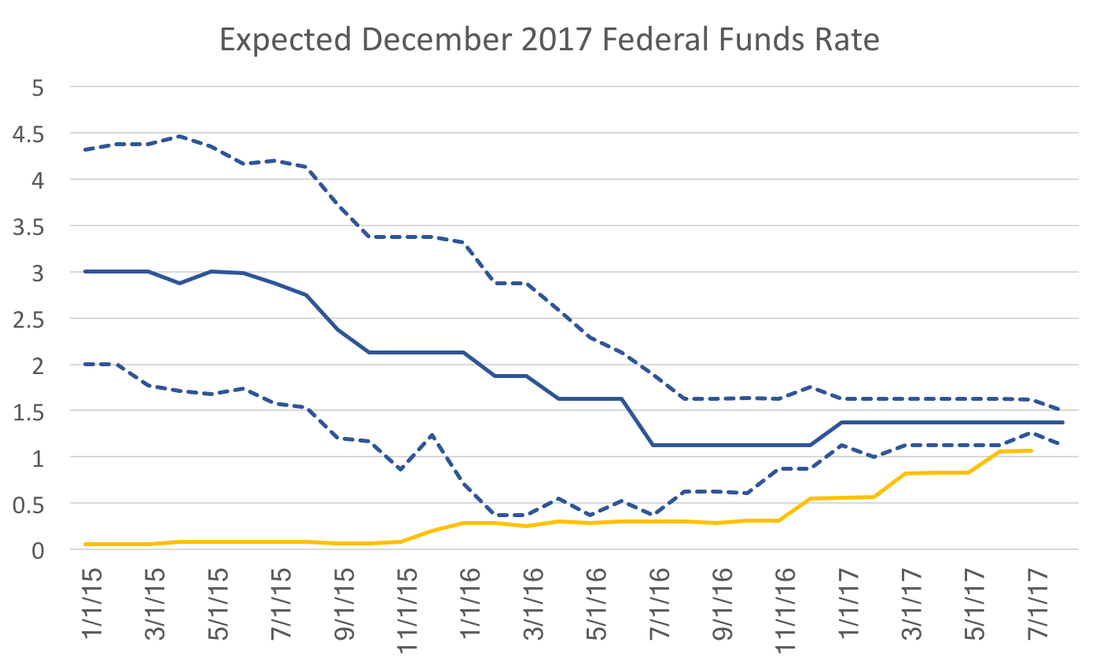 Instead consider the federal funds rate. These expectations, more so than those for inflation, driven by mostly by policy statements and projections released by the Federal Reserve. It is therefore not surprising how high expectations were at the beginning of 2015 and how quickly they have fallen over the past 2 years. In 2015 the discussion was over normalization of policy or "the lift-off," but the data at the time did not support action at that time. As policy statements and Fed projections became more clear expectations dropped quickly. Notice also the drop in uncertainty, a point I have emphasized in a previous post on federal funds rate expectations. The drivers of inflation and the federal funds rate have no direct impact on the bottom line of the forecasters or the firms for which they provide their forecasts. However, take ten-year government bond rates for example: 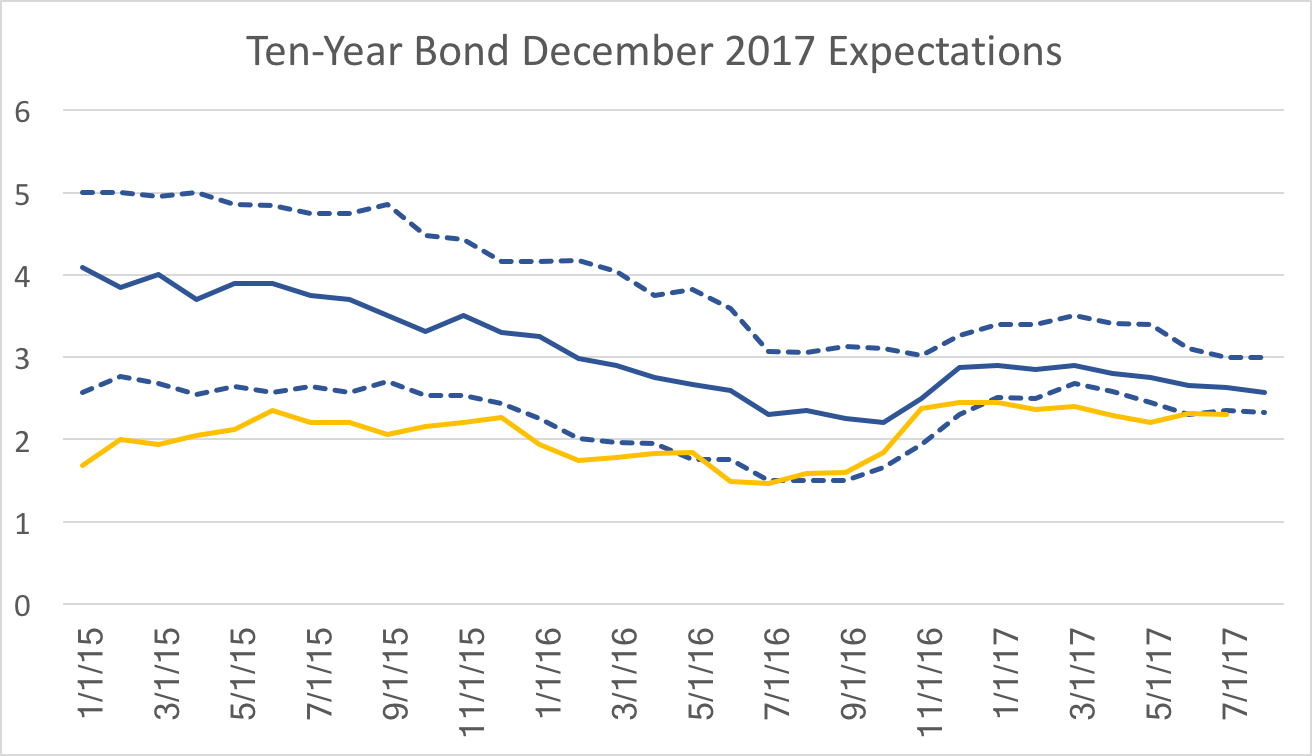 These expectations more closely follow the path of the actual bond rates even 2-3 years in advance of the realization. While bond rates should, in theory, be just as sensitive to monetary policy one would expect a similar pattern, however the gap observed at the beginning of this series does not appear as wide and the overall time-series movement between expectations and actual observations are remarkable similar.
How we think about long-run and short-run expectations depends critically on the relative importance of the outcome to our objectives. The current administration is considering a policy to curb legal immigration. In fact, the president's populist message about immigration certainly helped him win the election. This post seeks to clarify some relevant statistics regarding immigration. First, the number of legal immigrants to the US has been steadily increasing since World War II: 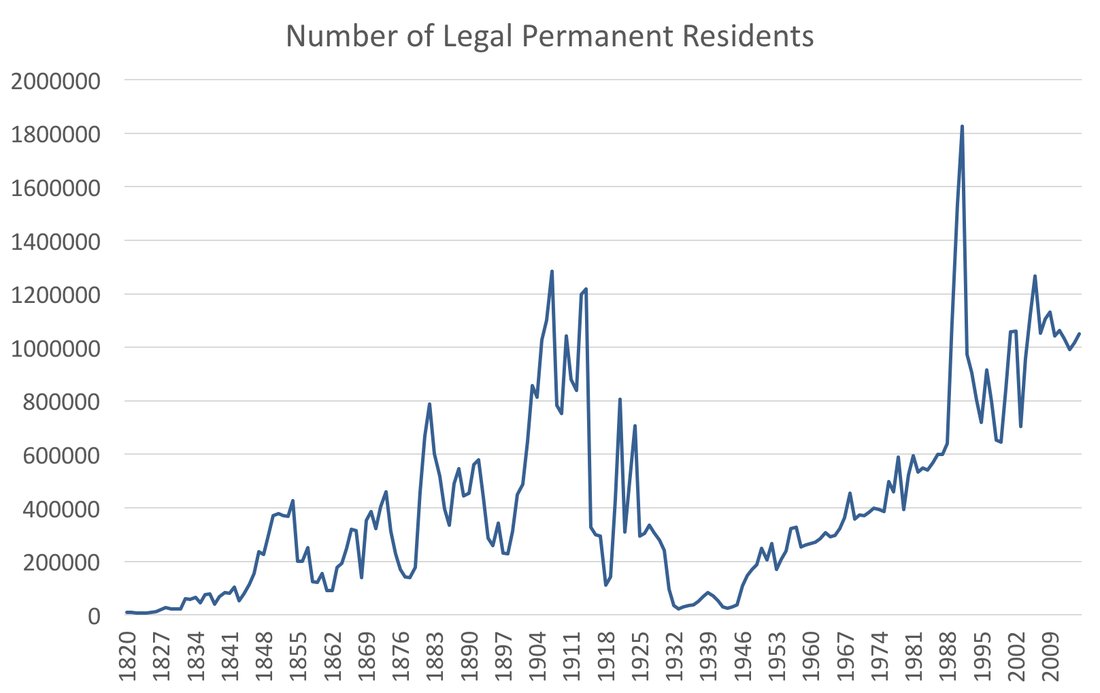 However, as percentage of US population, that increase is muted particularly in comparison to the pre-World War era: 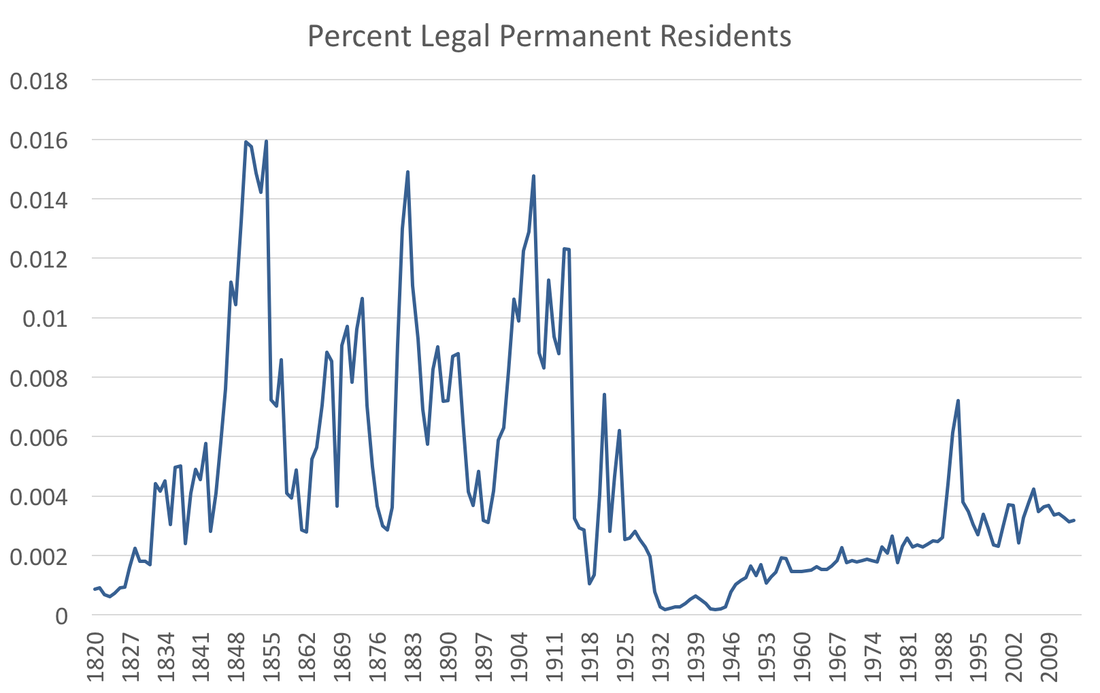 The percentage of legal permanent residents is increasing, and as many economist have noted, that may not be a bad thing. One point that has not been mentioned, as far as I know, is whether the US has immigrants pouring into it's borders, as the populist narrative might have us believe. Certainly in terms of raw numbers that may be true, but if we compare the US to several developed countries we see the US does not have a substantial amount of immigration: 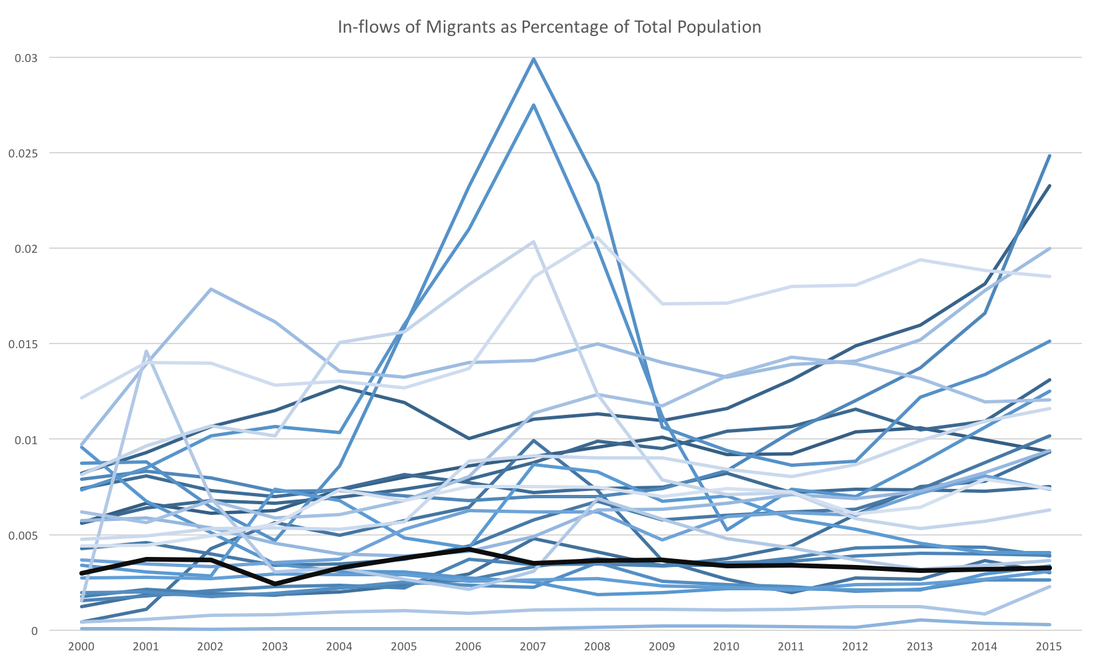 In the graph above the black solid line is the US and the other blue lines are OECD countries minus the former USSR countries. Clearly the US is not remarkable in terms of immigrants. The narrative of protectionist policies for legal immigration seems to lack grounding in facts.
Note on data sources: US imigration statistics come from the Migration Policy Institute. US population statistics come from Measuring Worth. And the migrant in-flow data comes from the OECD. A couple of months ago I wrote about the surprising decline of Federal Funds rate uncertainty in the WSJ economic forecasts. This post revisits that topic presenting a revised version of the data. Unfortunately, the revisions do not look as favorable for the Fed, but it still looks as though the Fed is effectively communicating their policy trajectory. 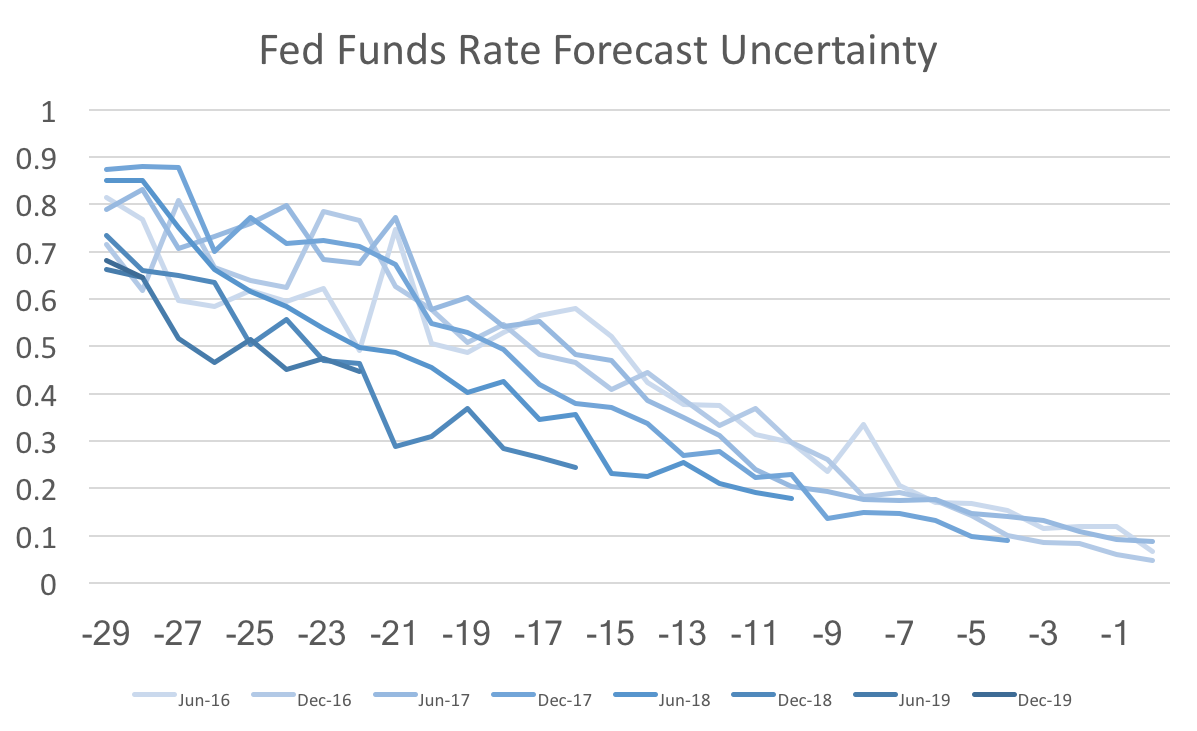 The graph above shows forecast uncertainty (std deviation of fed funds rate forecasts) for several future forecasts. The x-axis is the number of months out from the date being forecast. The striking feature of this graph is that the darker lines have shifted lower over time. This is more or less what I discussed in that previous post. However, when I looked back at the data (with the new forecasts add in) I noticed some anomalies and reweighed those results by the standard deviations of the payroll employment forecasts. 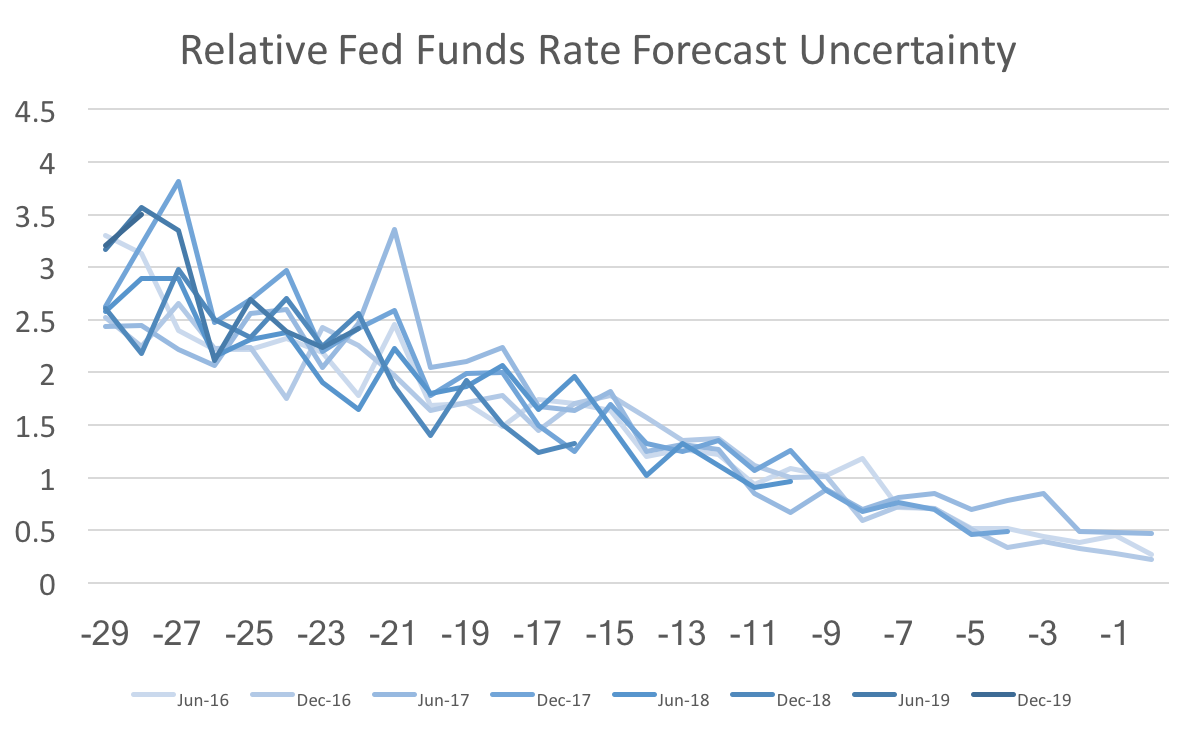 Once we recalculate federal funds rate uncertainty relative to the general level of uncertainty we find almost no change in fed funds rate uncertainty. If instead we calculate the same relative uncertainty for 10-year bonds, then we actually find that forecast uncertainty for 2019 is higher than normal: 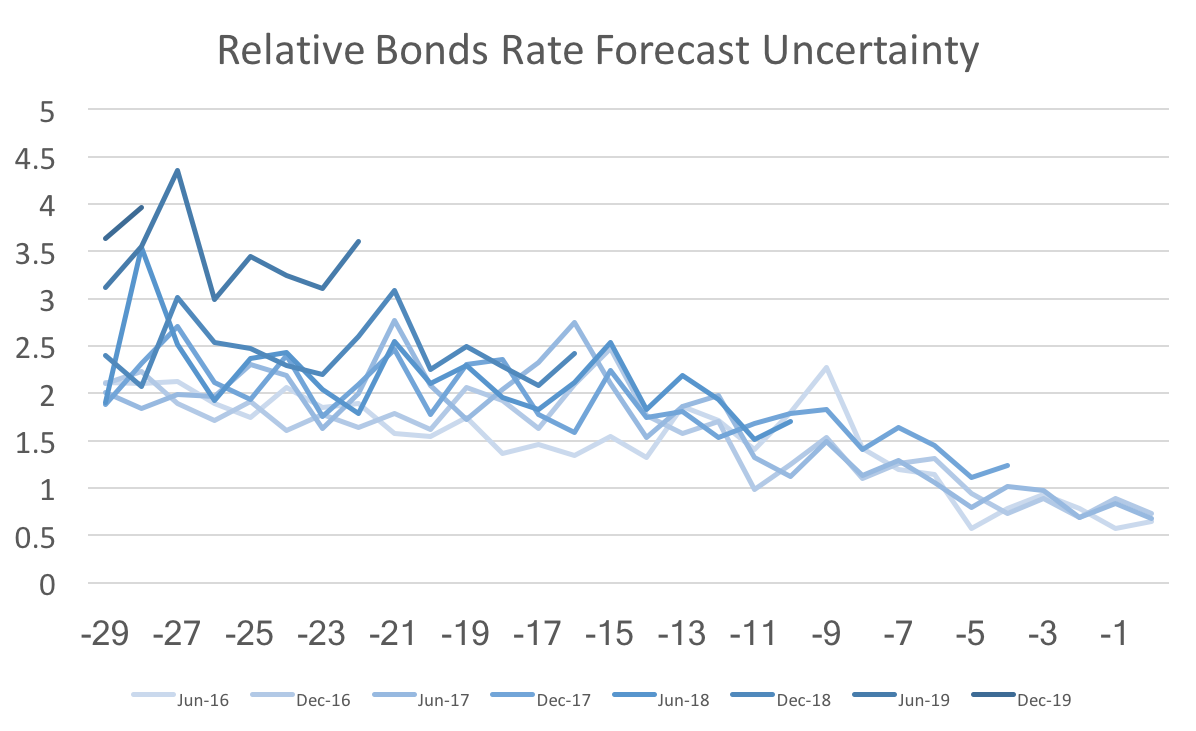 Since there has not been a dramatic shift in the more recent 2018 and 2017 forecasts, I suspect that the additional uncertainty is due to some forecasters projecting a recession (or at the very least a slow growth economy) while others foresee a continuing economic boom. To further support that claim we can see a similar pattern in quarterly GDP forecast uncertainty: 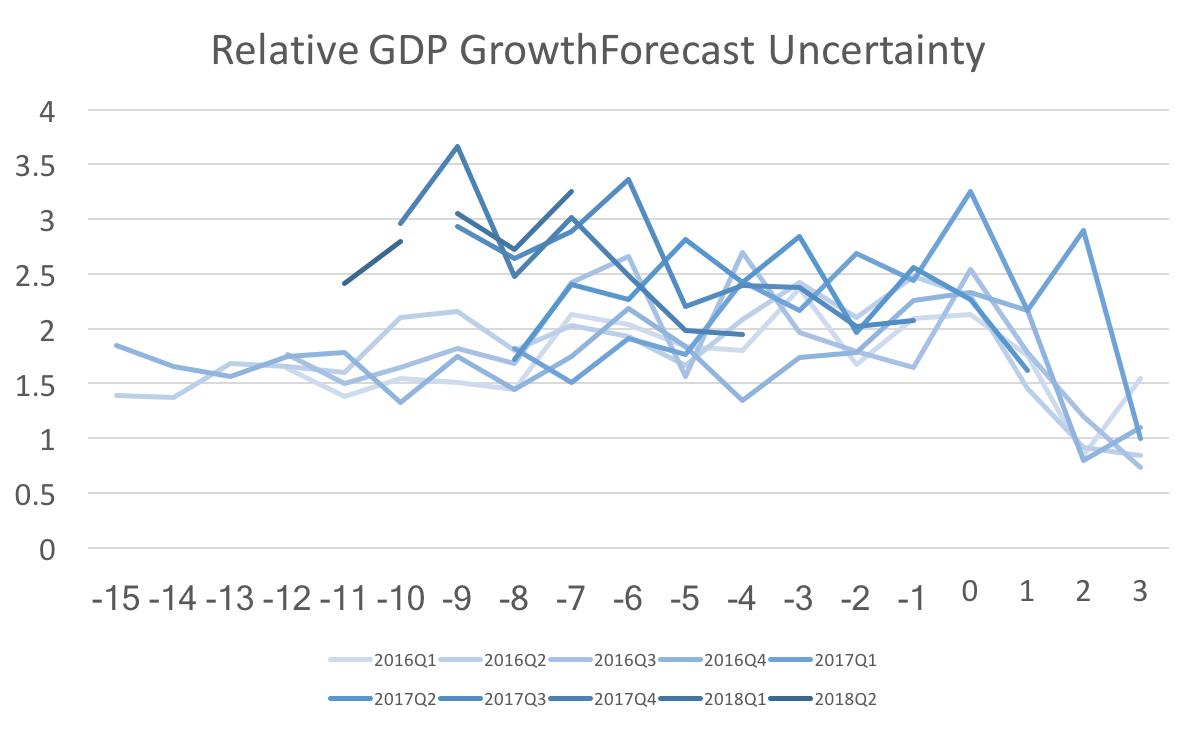 The forecast uncertainty of the Federal Funds Rate has remained similar to the past, relative to payrolls uncertainty. However, other variables appear to be getting more uncertain relative to payrolls uncertainty. For those facts to line up forecasters must understand and believe the Fed's announced policy trajectory.
In preparing to teach Econometrics this Fall, I found very few online or textbook sources that visually explain what happens in a regression. This post attempts to just that using Galton's height data. This data comes from the paper that provided the world with the term regression. An econometrician might use this data to answer whether a father's height influences the height of his offspring. (The analysis below could just as easily be applied to the mother's height) I would like to illustrate what happens in a regression using simple scatter plots. This first graph shows the data sorted by height, which is centered around 66.7 inches. 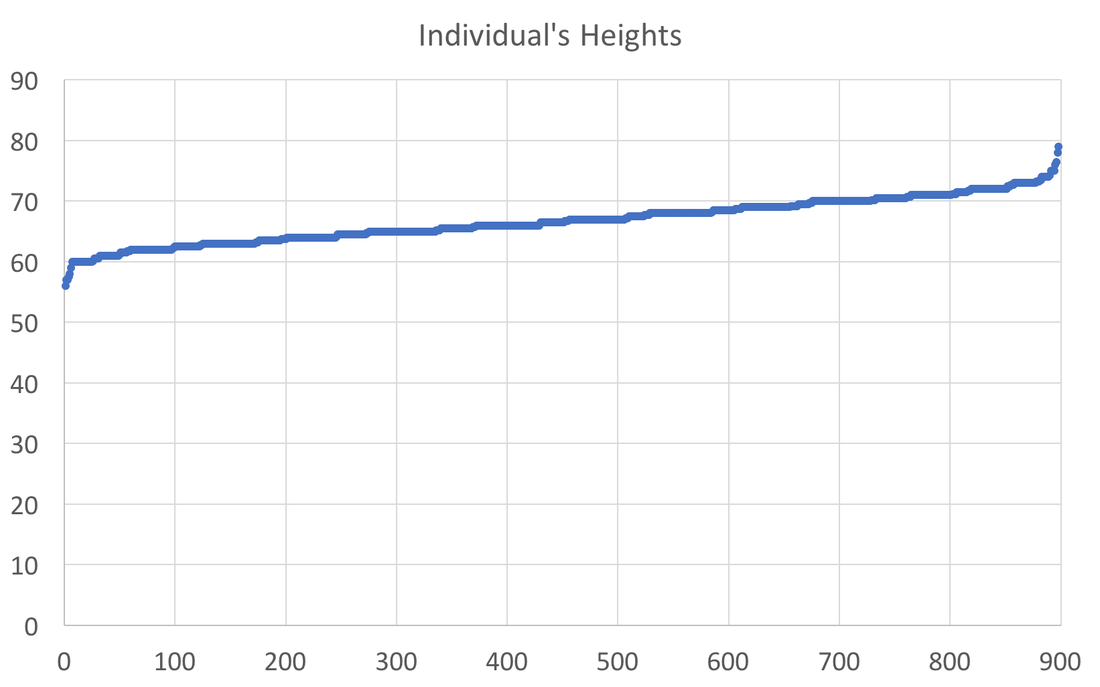 A regression attempts to find statistical relationships between variables (like height). One way to think about this is putting the data into different bins to see whether there are any differences. The most obvious bins that jump to mind when thinking about height is gender. The graph below first sorts by gender and then by heights: 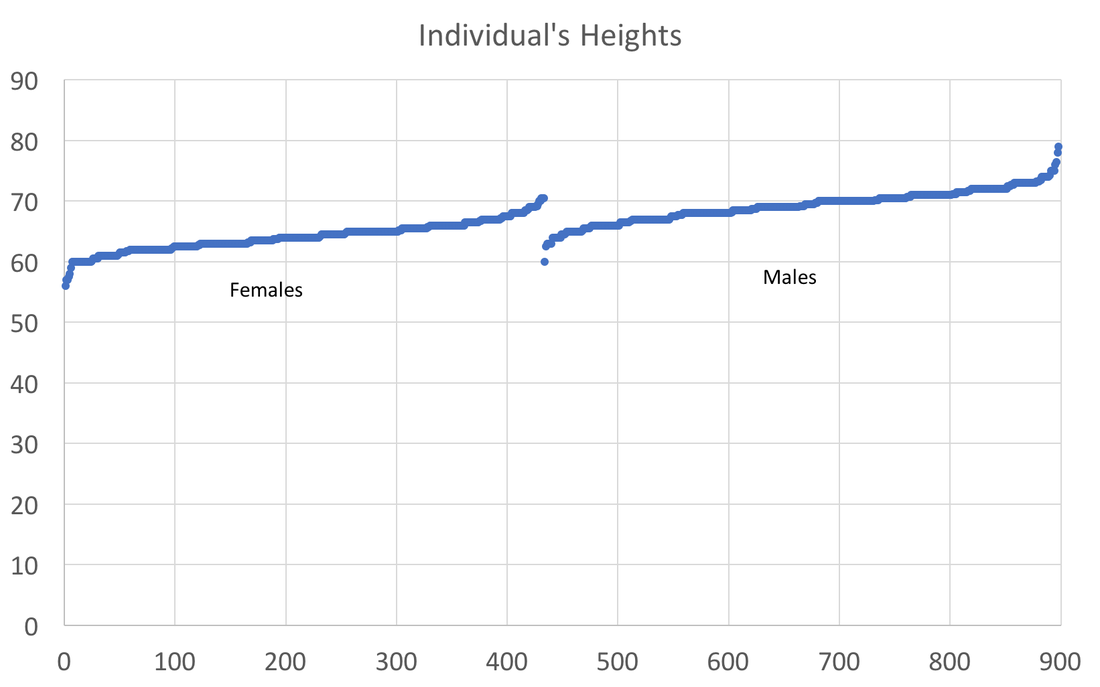 There is a clear difference between male and female heights. Almost half of the male height observations are above the tallest female observation. This should not be surprising, however it does provide the basic insight to how regressions work. The question a regression asks is, "if I observe someone to be a Female, what is their height?" The degree of statistical significance describes how distinct the bins are from one another. That is, the majority of the female observations are below the majority of the male observations. (the average for the women is 64.1 and 69.2) Now take that basic idea of bins to something like the fathers height. First sort the data in a similar manner, tall vs short fathers (cutoff being 70 in.). 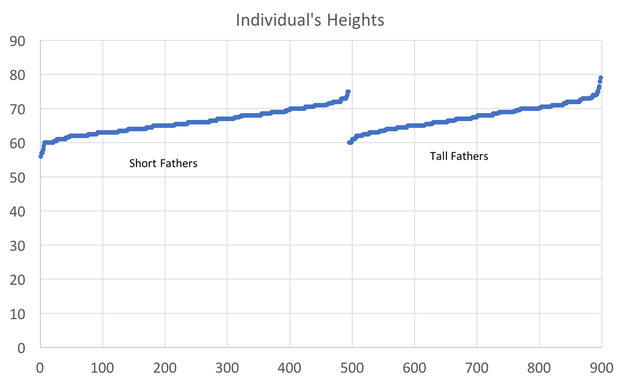 Here we see a very similar story, but not as stark as the difference between male's and female's heights. That means that the statistical significance of father's height is weaker, because we know that a person with a tall father should on average be taller, but additional variation still exists within these bins. If I increase the refinement of the filter to three bins we can find a break down like this: 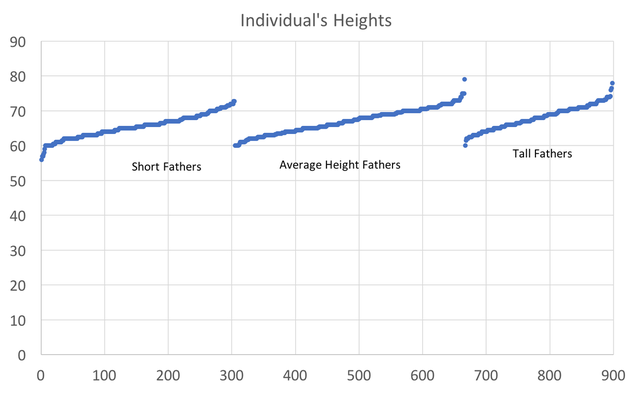 Keep going in this way and we can increase the number of "bins" to include each reported height. This makes a graph that has many bins: 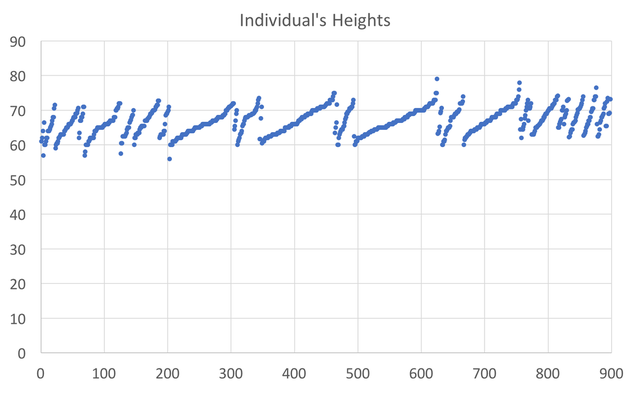 We can still see the general trend, taller fathers produce taller offspring, however there is a fair amount of variation within the different height bins, so much so that we cannot be very confident about how much paternal height influences offspring height. Instead, let's look at the classic visualization of regression, the line of best fit: 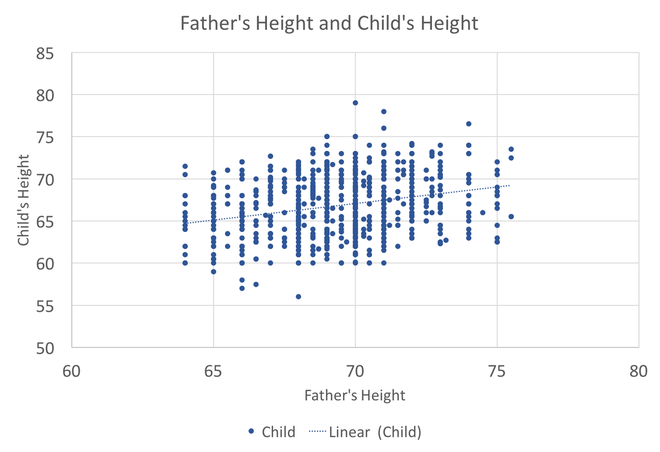 At first glance, our question has been answered; a father's height has a marginal influence their offspring. The underlying statistics will tell us that we can only explain 6% of the variation and that a father who could magically be one inch taller would produce offspring approximately 0.389 inches taller. However, we've forgotten the knowledge we gained about the great differences between male and female heights. The graph below visualizes the impact of how father's height influences a child's height conditional on whether that child is male or female. 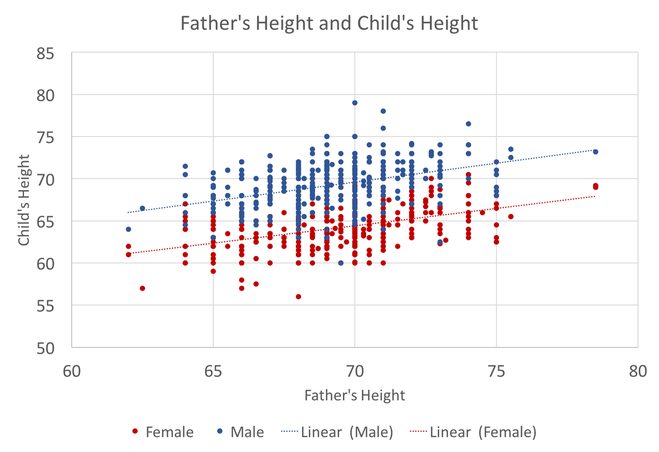 We can see a clear distinction between the males and females. In addition, we are able to explain much more of the variation (approximately 20%) and the influence of a father's height has increased to 0.43 inches per inch. The increase itself is not that important, however the confidence with which we can make that claim has increased (which is related to increase in explanatory power).
This illustrates the science and art of regression analysis. The technique looks for order between observations that exhibit variation. The art comes from understanding when (and what) it is appropriate to include or exclude from a regression. In this case, including an additional variable (gender) helped explain the variation and gave a better answer to our original question. The August WSJ forecasts are out, and it is another mixed bag, though mostly negative. On the positive side, third and fourth quarter GDP forecasts went up by a tenth of a percent. Forecasts for unemployment through 2019 all went down and payrolls employment increased slightly. However, annual growth for both 2017 and 2018 ticked down slightly. In addition, all the consensus federal funds rate forecasts decreased, indicating lower expectations for the future job markets. This coincides with lower expectations for inflation through 2019. 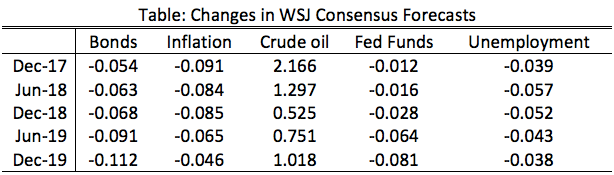 These changes in forecasts reflect the recent low inflation numbers, despite the upbeat employment report. St. Louis Fed President Jim Bullard recently commented on inflation and current monetary policy, which provides a window into the subdued outlook by the WSJ forecasters. In Bullard's view, low commodity (mostly oil) prices have been having the greatest impact on headline inflation, which, he believes, will outweigh any impact of any future improvements in the job market.
If we take that insight as given, the WSJ forecasters are predicting increase in oil prices (and housing prices) over the coming years. Should those increases materialize, the Fed might final realize their two percent target inflation rate. Economists model the economy, which really means we model thinking and decision making. A post from a few weeks ago showed that professional forecasters display less future federal funds rate uncertainty. Could this reflect a more general trend of individuals having more information about the federal reserve system? The most visible member of the Federal Reserve is the Chair, and google trends provides excellent data on the relative frequency of Fed Chair searches: 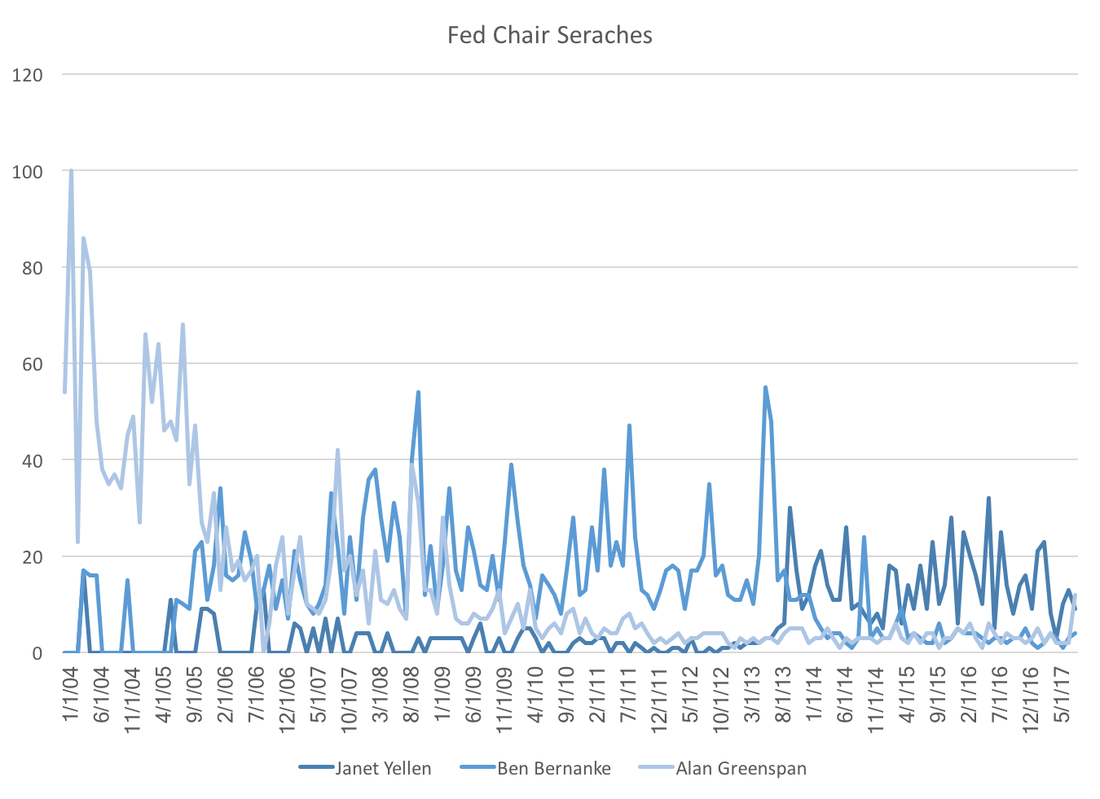 As each chair transitions we see the appropriate shifting of search traffic from one person to the other. The notable difference the relatively low number of searches of current chairwoman Janet Yellen. It appears this is an artifact of declining interest in the Federal Reserve searches in general: 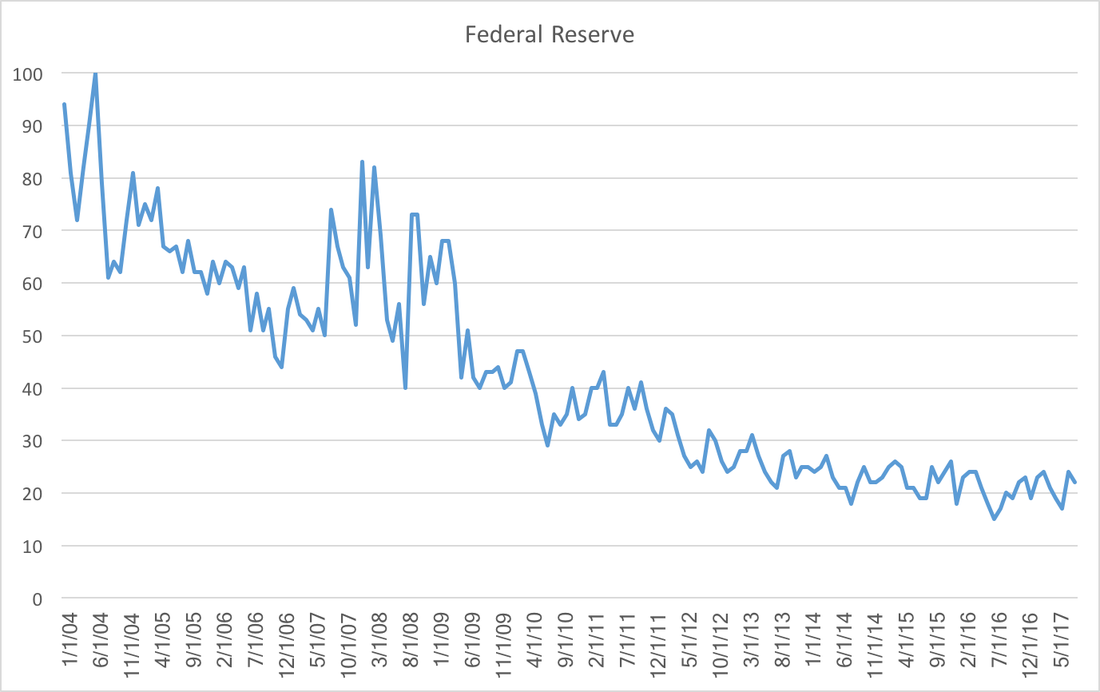 Re-weighting the first graph by the second we see that relative to Federal Reserve searches, Janet Yellen has been searched for at least as much previous Fed Chairs: 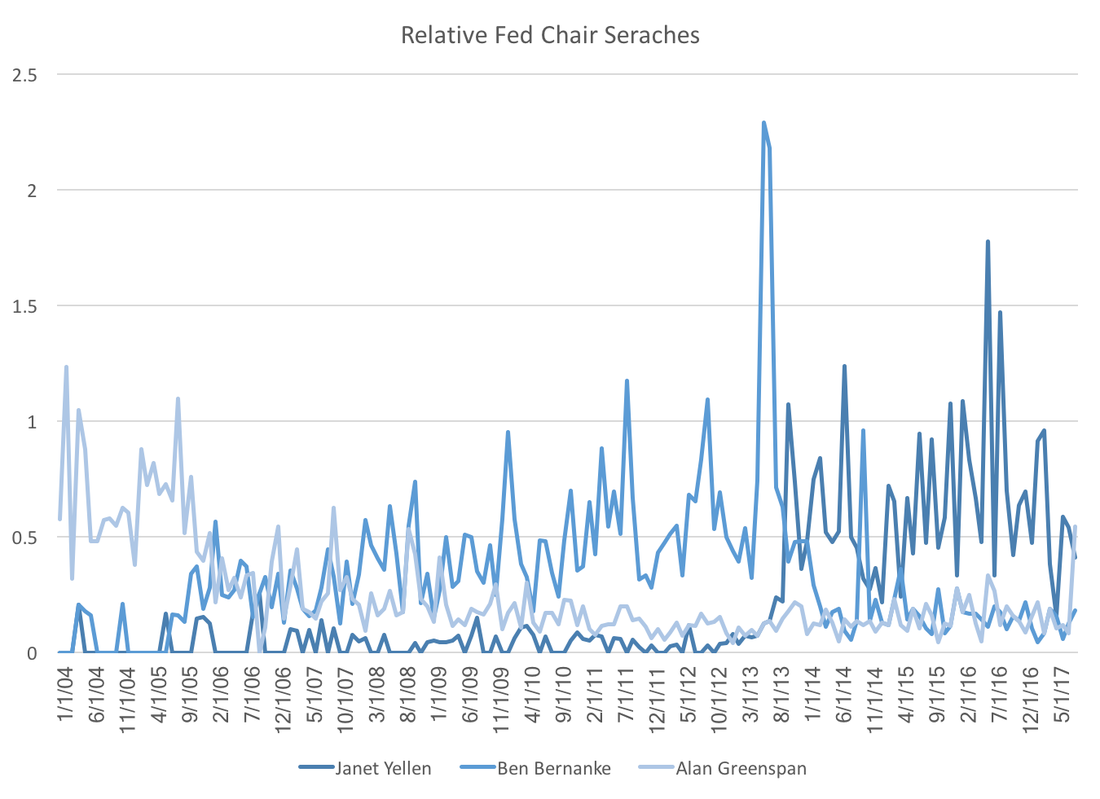 While it is nice to know that there does not appear to be a gender bias, a puzzle remains. Why has fed funds rate forecast uncertainty decreased while interest in the federal reserve has waned? Perhaps searches have declined because the Federal Reserve has done a better job at communicating future policy, which eliminates the need for gathering additional information.
Today marks the three month anniversary of this website and blog. I will be taking a brief hiatus from blogging over the next week.
Thank you all for reading these posts. I hope that you have enjoyed reading as much as I have enjoyed sharing my love of facts, figures and forecasts. Enjoy this list of my favorite posts from the first three months:
|
Archives
May 2018
Categories
All
|